Distributed systems chronicles: Key value store (1) - Architecture and Protocol
Motivation and Goals⌗
I am starting this series of blog posts to help students and young professionals that didn’t get a chance to have a college degree, or have a distributed systems course in university, to get a better grasp on some of the building blocks of distributed systems such as key-value stores, load-balancers, distributed queues … in a practical way.
The goal is to end up at the end of the series with a bunch of small working systems that helped shed the light on some of the concepts and problems faced when writing distributed software.
Language consideration⌗
Choosing a programming language to achieve the goals stated above is not gonna be easy, especially that most of the readers (and me included) will have different opinions on what they think is a better programming language, so I will pick the programming language that I think most suitable for building the system at hand, for a distributed key-value store I choose Rust.
Rust is a powerful language that has both those higher order concepts found in functional languages and the raw performance and control that is given by languages like C++ and it also comes with Fearless concurrency and a strong Memory safety model, and it does all the above with no runtime.
The KV store⌗
Think of the simplest key-value store that you can build, and that’s going to be
our first starting point, an in memory HashMap like API accessible via TCP.
We want to support (at first at least) three types of operations:
SET KEY VALUE: store the given value and make it identifiable with the given key, the key and value are considered raw strings, it’s the client’s responsibility to make the transformation from a RAW string value to a known type.GET KEY: get the value associated with the given key, this returns the raw string (if any) identified by the given key, which has been set by a previous call toSETCLEAR KEY: delete the key from the store, and any data associated with it, if the key does not exist this should be a no-op.
Overall architecture⌗
This is the overall architecture, it doesn’t have anything that you wouldn’t expect following what I described above, It’s a canonical client-server architecture, we will iterate on this design as we go along, by adding more details and showing off additional constraints, but it’s good to start somewhere:
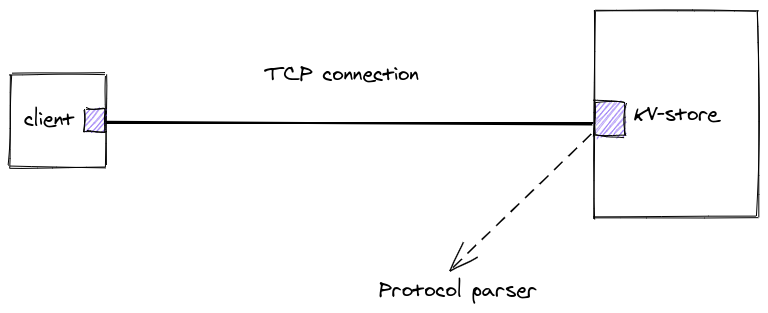
Communication protocol⌗
The first thing that we should work on, is how does the client communicate with the kv-store.
Requirements for the protocol:
Simple: We want the protocol to be simple to parse and reason about, We don’t want to spend a lot of time doing just parsing and converting raw bytes into actual commands.
Language agnostic: We should be able to read and write the commands from any programming language, so using language specific serialization facilities (like Java’s serialization) is out of the question.
So a protocol proposal could be as follows:
Sending a SET⌗
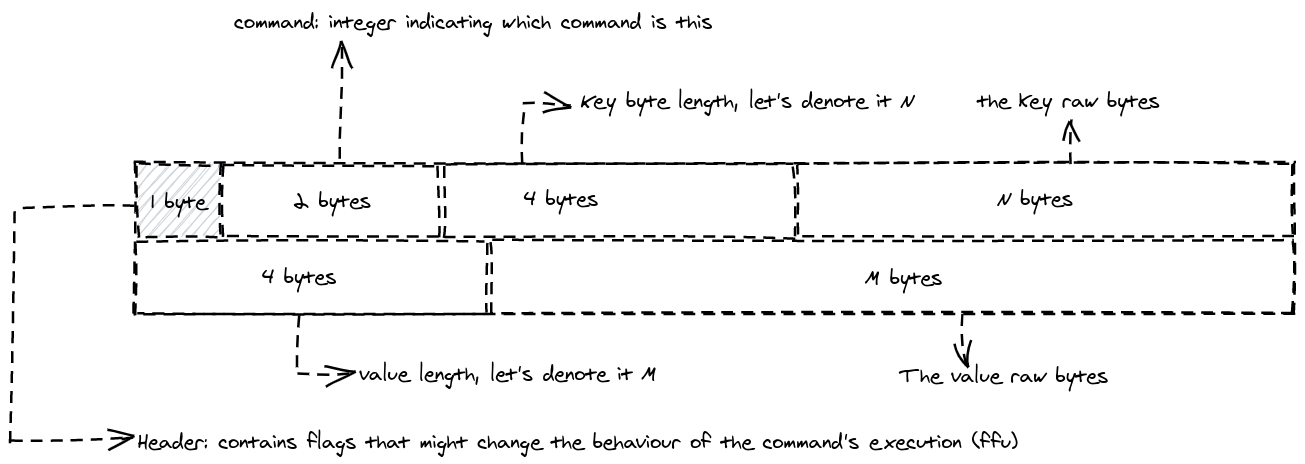
Sending a GET⌗
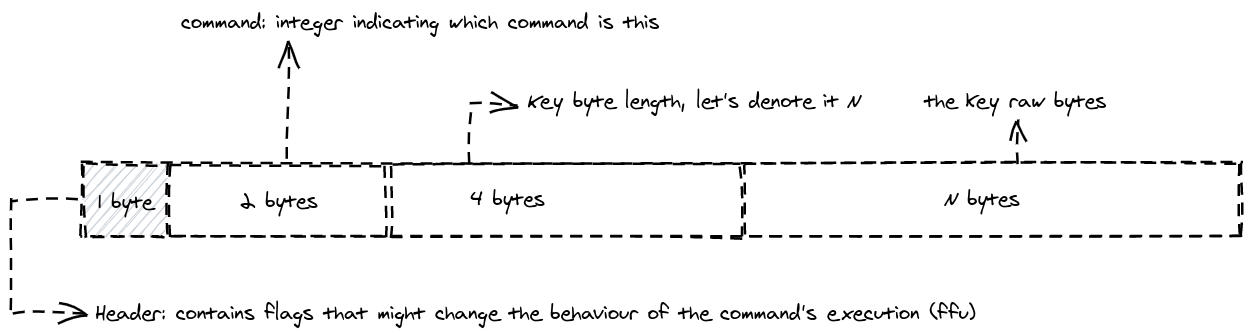
Sending a clear⌗

From the above descriptions of the different command protocol, it’s fair to say that it respects the requirements defined above, as it can easily be parsed as we will show below, and it is language agnostic, one can imagine writing a simple client for this in any programming language.
One thing that we didn’t describe in the protocol is the Response model, What happens when a command succeeds? How does the response look like? What if it fails?
Luckily we don’t have that many commands, and from the ones that we have now, every command can have three possible outcomes:
- Succeeds with no data to return
- Succeeds with some data to return
- Fails with a message
From the above states, we can come up with a model that always have a bit
indicating the status (either success or failure), and some trailing bytes for a success response data, or
a simple "OK" if the command does not expect data back (like CLEAR). The same byte could be
used to store the error message in case of failure, So the model will look like this:
Response⌗
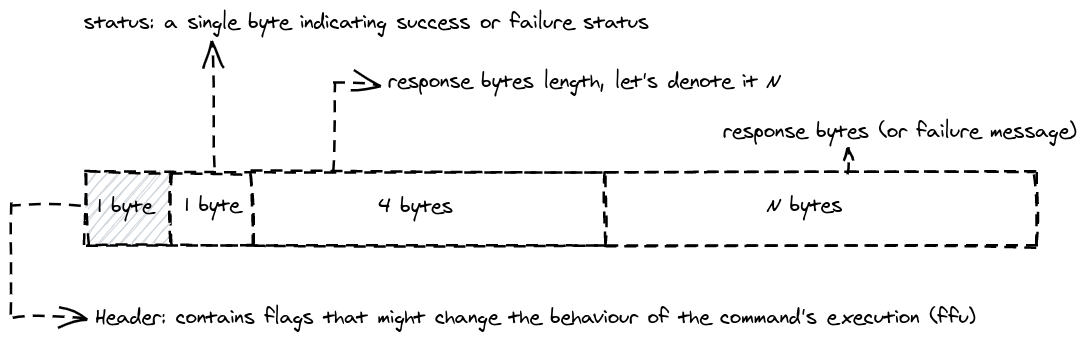
Implementation⌗
To start implementing this, we will create a new project using the cargo new
helper (I am assuming that you have rust or your favourite programming language
environment setup), the initial directory structure should be something like
this:
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
The protocol implementation could be used on the server and client, so it’s better to have it in its own crate (crate is a rust term that refers to a library), but for simplicity reasons I will keep it in the same crate for the time being.
I will create a directory under my src folder called protocol that will
contain all the protocol implementation, and will make it easier to migrate
to its own crate later on.
What we want to have at the end of this blog is an implementation of this function:
fn parse(data: &mut Cursor<&[u8]>) -> Result<Command> {}
I will try to elaborate on the signature:
The Cursor<&[u8]> is a facility datastructure that allows us to wrap buffer-like
structures and be able to manipulate them easily, since we are manipulating
buffers of bytes i.e u8 the cursor’s generic type is [u8]
The Result represents value or an Error while trying to obtain it, and this fits
our use case perfectly, as bytes could be corrupt, and we wouldn’t be able to
parse the byte stream to a Command instance.
The Command is a Rust enum that represents the set of commands available to the
server, and it looks like this:
#[derive(Debug)]
enum Command {
Set(String, String),
Get(String),
Clear(String),
}
First, let’s make some utility methods to easily convert from raw bytes (i.e
[u8] to types such as u32 and String
/// Get a single byte from the cursor and advance it by one byte
fn get_u8(cur: &mut Cursor<&[u8]>) -> Result<u8> {}
/// Get a `u32` from the cursor and advance it by 4 bytes
fn get_u32(cur: &mut Cursor<&[u8]>) -> Result<u32> {}
/// Get a `String` from the cursor
///
/// This function assumes that the cursor is at the first byte of
/// string length, so it will first read the first 4 bytes of the length `n`
/// then read `n` bytes that makes the string.
fn get_string(cur: &mut Cursor<&[u8]>) -> Result<String> {}
The implementation is pretty straight forward, I left it out to keep it short. Having these functions will make reading the data from a stream pretty easy to write
/// Parse a single command from the current byte stream.
pub fn parse(data: &mut Cursor<&[u8]>) -> Result<Command> {
let _header = get_u8(data)?;
let command = get_u32(data)?;
match command {
0 => Parser::parse_get(data),
1 => Parser::parse_set(data),
2 => Parser::parse_clear(data),
_ => Err("Unknown command number".into()),
}
}
fn parse_get(data: &mut Cursor<&[u8]>) -> Result<Command> {
let key = get_string(data)?;
Ok(Command::Get(key))
}
fn parse_set(data: &mut Cursor<&[u8]>) -> Result<Command> {
let key = get_string(data)?;
let value = get_string(data)?;
Ok(Command::Set(key, value))
}
fn parse_clear(data: &mut Cursor<&[u8]>) -> Result<Command> {
let key = get_string(data)?;
Ok(Command::Get(key))
}
And that’s all the implementation for the read path, you can also notice that it matches what was described previously in the protocol specification.
As parsing any data type can fail, all the parse_* methods return
a Result type, and the error is propagated at the call site using the ?
operator.
For the response type, which does not have the same prefix as the other commands, it should be parsed a bit differently:
The enum looks like this:
#[derive(Debug)]
pub enum Response {
Ok(String),
Error(String),
}
The code to parse it is quite similar to what we did before:
pub fn parse_response(data: &mut Cursor<&[u8]>) -> Result<Response> {
let _header = get_u8(data)?;
let response_type = get_u8(data)?;
let response = match response_type {
// The success response
b'0' => Response::Ok(get_string(data)?),
// The failure response
b'1' => Response::Error(get_string(data)?),
// A corrupt response
_ => Response::Error("Unknown response type".into()),
};
Ok(response)
}
The code part for the write path is quite similar, we will define a Writer
struct to attach our methods to, the struct itself is just a marker, but it
can contain state later as we see fit.
The new thing that will be added is a dependency on a library called tokio.
The support for asynchronous programming in Rust is a join effort between the language team and the libraries, the tokio library provides an asynchronous runtime for doing network programming, with numerous utilities to help develop highly performant and scalable software, but for now we are only going to leverage a small subset of its features.
All of our data reading has been done on a Cursor type in a synchronous
way, that’s because the cursor assumes that the data is already in memory, later
on we will need to read this data from an open socket asynchronously, but for the
write path, data will be written directly to the output stream asynchronously
without copying it to another intermediate data structure, it’s just easier
/ faster this way.
We will introduce two types for this:
tokio::net::TcpStreamwhich is an abstraction over … well a TCP stream, you can write / read bytes from it asynchronously.Note: there is a
std::net::TcpStreamprovided by the standard library which does synchronous read/write operationsBufWriterwhich will handle bufferingwrite_*calls to the underlyingTcpStreamthus reducing the number of write syscalls that we have to make.
So the code for the write path will be something along the lines of:
pub async fn write_command(buf: &mut BufWriter<TcpStream>, cmd: &Command) -> Result<()> {
match cmd {
Command::Get(key) => {
buf.write_u8(0).await?;
buf.write_u16(0).await?;
write_string(buf, &key).await?;
}
Command::Set(key, value) => {
...
}
Command::Clear(key) => {
...
}
}
Ok(())
}
Similarly to write a response
pub async fn write_response(buf: &mut BufWriter<TcpStream>, res: &Response) -> Result<()> {
match res {
Response::Ok(msg) => {
...
}
Response::Error(msg) => {
...
}
}
Ok(())
}
I omitted some code details as they are pretty straight forwards, and I don’t want to bind the blog post to Rust too much.
The code uses Rust’s async/await similar to other languages, to provide
asynchronous running code that reads synchronous.
We write the bytes depending on the type of the entity at hand, according to the simple protocol that we came up with in the first section.
Conclusion⌗
In this post we discussed the project and its ultimate goals, and we provided the detailed version of the protocol that we are going to use to communicate with our server.
For the rest of the code, you can find it here.
See part 2 of the series, stay tuned.